|
|
 丫婷﹁]]
| 未知
丫婷﹁]]
| 未知
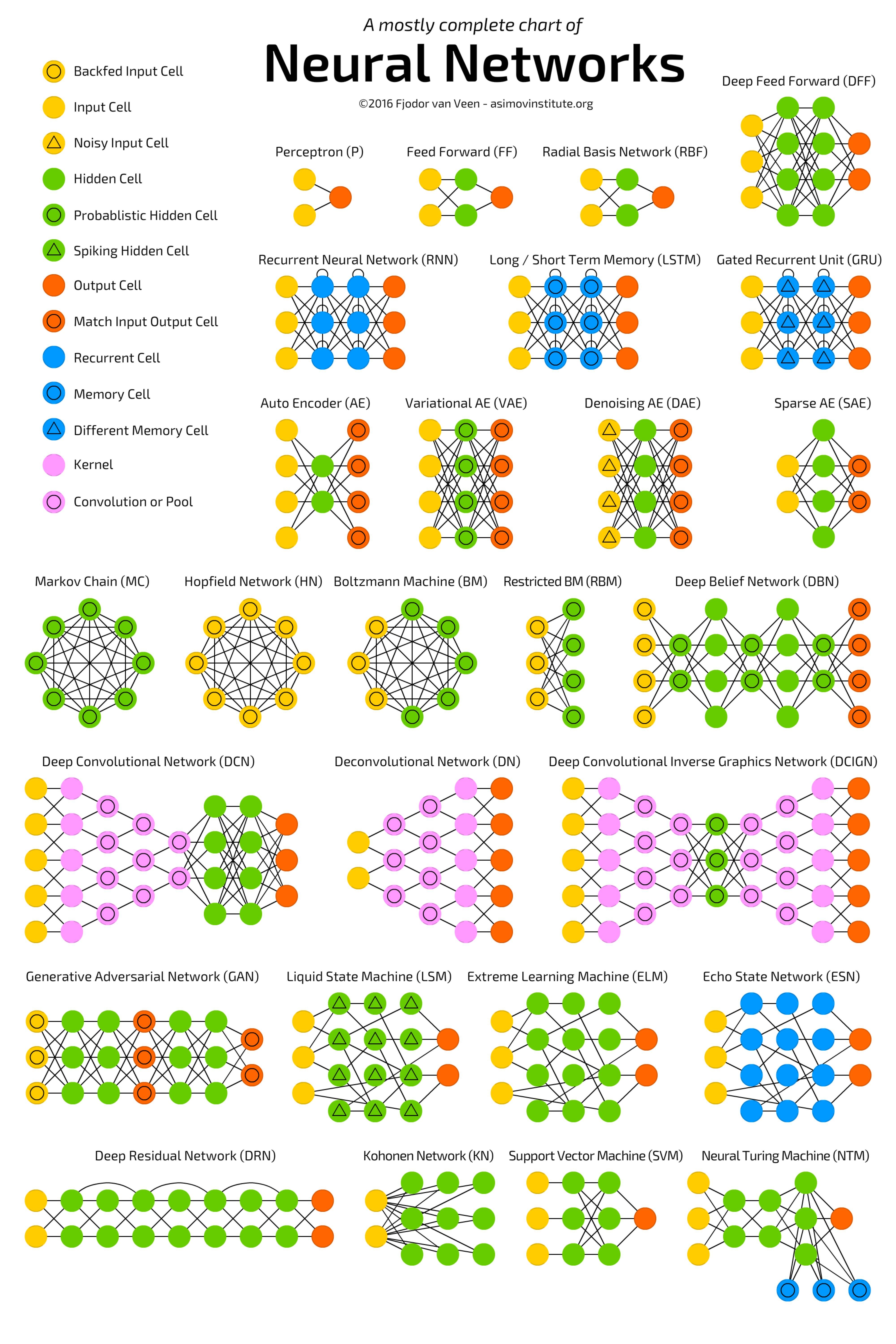
大学是信息安全,可以说是IT众小专业中和机器学习距离最远的一个。读研转机器学习,也许经历对你会有帮助。
假设你有程序员的基础,懂至少一门语言,和基础的数学知识。
首先,可以先找一个机器学习的工具玩起来。比如说现在很火的MXNet,Tensorflow…等
这个过程是为了培养亲切感,对机器学习有初步感性认识。
我来做毕设前,导师让我看语言模型。我对着一篇大牛的博士论文看了半个月,过来之后,导师让我改一个复杂的模型,我是懵逼的。
理论和数学公式我都懂!可是这坨高大上的神经网络在计算机里到底是一个怎样的东西啊?…这是我当时内心真实写照。跑上了工具一切都清晰起来了。
所以现在带本科生,都是先跑上工具,然后继续后面的基础知识完备和深入研究。
有了感性认识以后,可以开始补机器学习的底层基础了。
首先是概率论,不确定你学过没,学过不用的话大概率也忘了,而且大概率当时学的时候并不知道这个有什么用。
矩阵理论和线性代数同理。
最优化理论也是重中之重。
这四个基础数学知识学完之后,可以开始学上层的基础了。
机器学习可远远不止是现在大热的神经网络。
推荐Andrew的笔记,很多节~网上有很多译版,即使是英文原版也非常全面易懂。
或者是最近也很火的西瓜书(周志华的机器学习)
做完以上几点就挺不容易的。
在学晦涩的数学和机器学习基础算法的同时,可以转转工具玩玩,实现一下最近比较火的模型。无论是语音,图像,NLP或者什么自己感兴趣的,调节调节。这个过程中,你一定对工具的上层代码都熟悉了。
到这一步:知道数学原理,精通基础经典机器学习算法,会用机器学习工具,会改工具,已经算一个比较合格的机器学习程序员了吧。
接下来,还想继续深入的话,工程方面可以选择读读工具的底层实现代码,涉及到cuda运算,或者进程调度,分布式编程这方面的。
自己完完全全写个神经网络,或者写个机器学习工具练练手。学习下GPU编程,多线程编程,多机多卡,分布式等等。
科研方面就可以在数学原理,模型结构,或者应用,数据上动动脑子做文章了。
未完待续… |
|
 用PixPix生成超酷炫电视壁纸
用PixPix生成超酷炫电视壁纸